Object Detection
Object detection combines classification and localization to identify objects in an image and specify their locations through bounding boxes. JustDeepIt supports multiple well-known deep neural network architectures, such as Faster R-CNN[1], YOLOv3[2], SSD[3], RetinaNet[4], and FCOS[5], to build object detection models for training and inference. The inference results can be stored as images with bounding boxes or a JSON file in the COCO format. The following image is an example of wheat head detection results with Faster R-CNN using GWHD datasset[6].

GUI
The GUI window for object detection consists of three tabs: Preferences, Training, and Inference. These tabs are used for setting common parameters, training models, and inference (i.e., detecting objects) from the test images using the trained model, respectively. Tabs Training and Inference are disabled until the settings in tab Preferences are defined.
Preferences
Tab Preferences is used for setting common parameters, such as the architecture of detection model, number of CPUs and GPUs to be used, and the location (i.e., directory path) to a workspace which is used to save intermediate and final results. The required fields are highlighted with orange borders. Detailed descriptions of the arguments are provided in the following table.
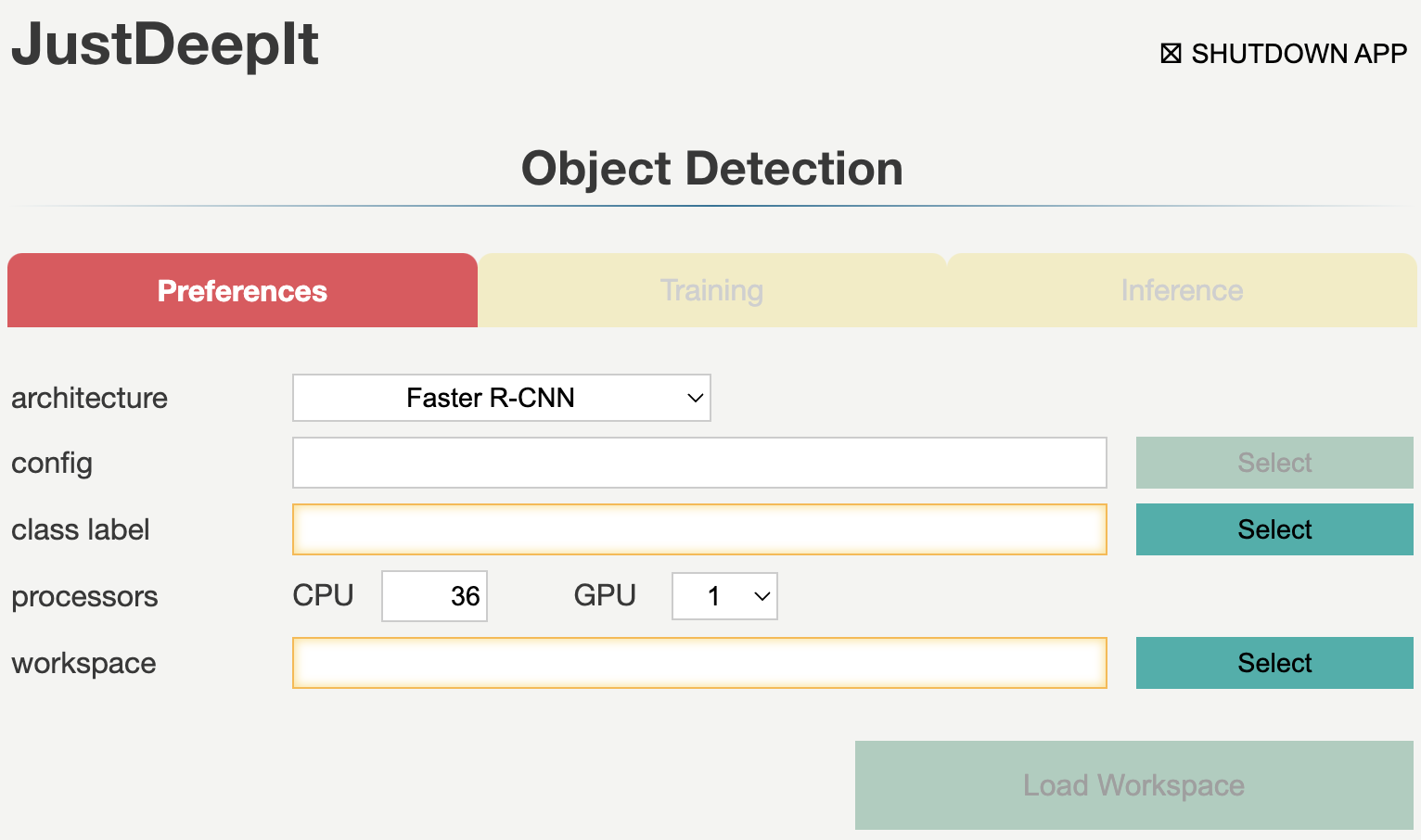
Argument |
Description |
|---|---|
backend |
The backend to build an object detection model. The current version of JustDeepIt only supports MMDetection as a backend. |
architecture |
Architecture of object detection model. If |
config |
A path to a configuration file of MMDetection or Detectron2.
This field will be activated when |
class label |
A path to a text file which contains class labels. The file should be multiple rows with one column, and string in each row represents a class label (e.g., class_label.txt). |
CPU |
Number of CPUs. |
GPU |
Number of GPUs. |
workspace |
Workspace to store intermediate and final results. |
Training
Tab Training is used to train the model for object detection. It allows users to set general parameters of training, such as the optimization algorithm, optimization scheduler, batch size, and number of epochs. Detailed descriptions of the arguments are provided in the following table.
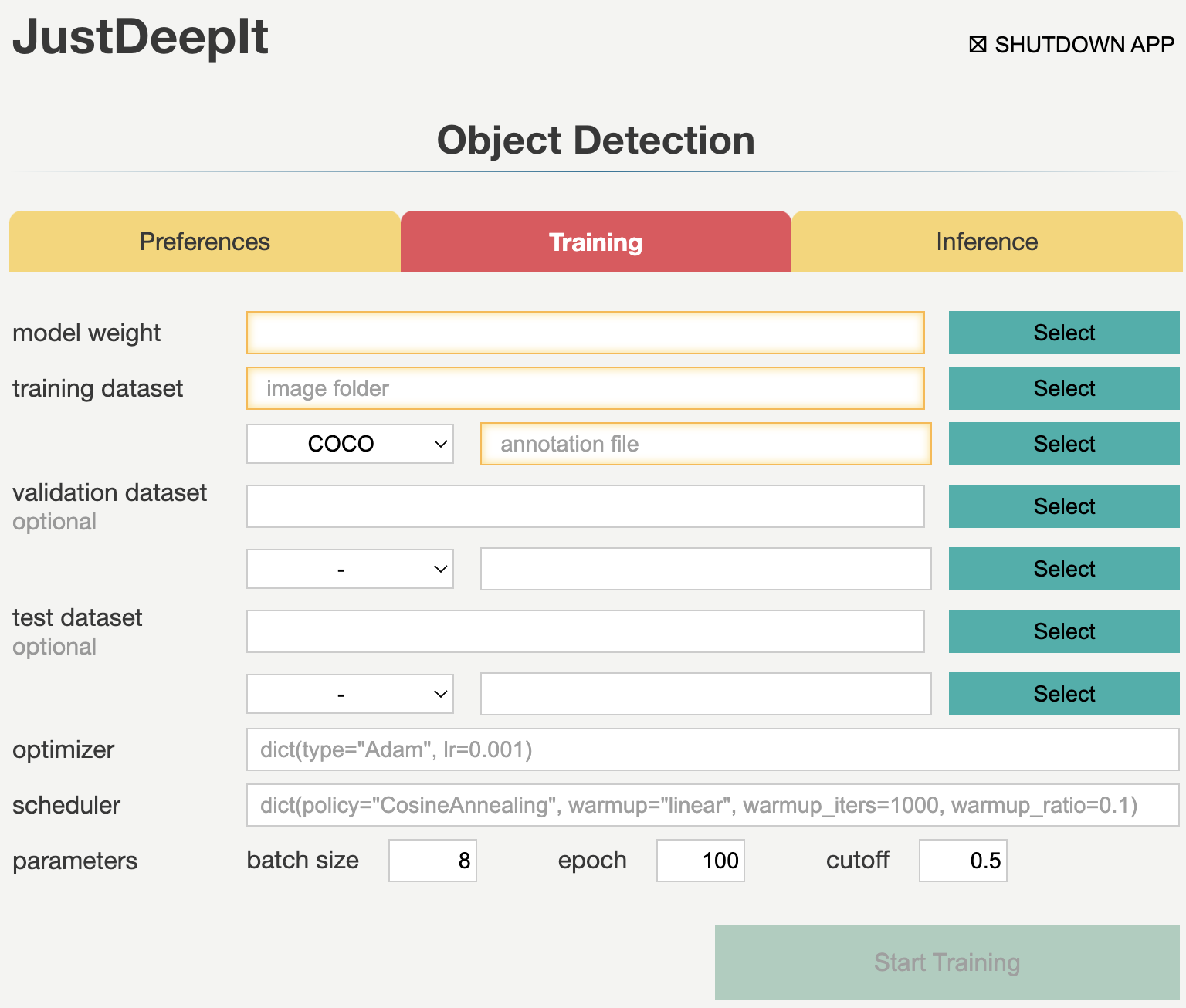
Argument |
Description |
|---|---|
model weight |
A path to store the model weight. If the file is exists, then resume training from the given weight. |
training dataset |
Information for training dataset. A path to a folder which contains training images; annotation format (COCO, Pascal VOC); and a path to an annotation file (COCO format) or a folder (Pascal VOC format). |
validation dataset |
Information for validation dataset. Left blank if no validation dataset. |
test dataset |
Information for test dataset. Left blank if no test dataset. |
optimizer |
A optimizer for model training. The supported optimizers can be checked from the MMDetection website. |
scheduler |
A scheduler for model training. The supported schedulers can be checked from the MMDetection website. |
batch size |
Batch size. |
epochs |
Number of epochs. |
cutoff |
Cutoff of confidence score for training. |
Inference
Tab Inference is used for detecting objects from test images using the trained model. It allows users to set the confidence score of object detection results and batch size.
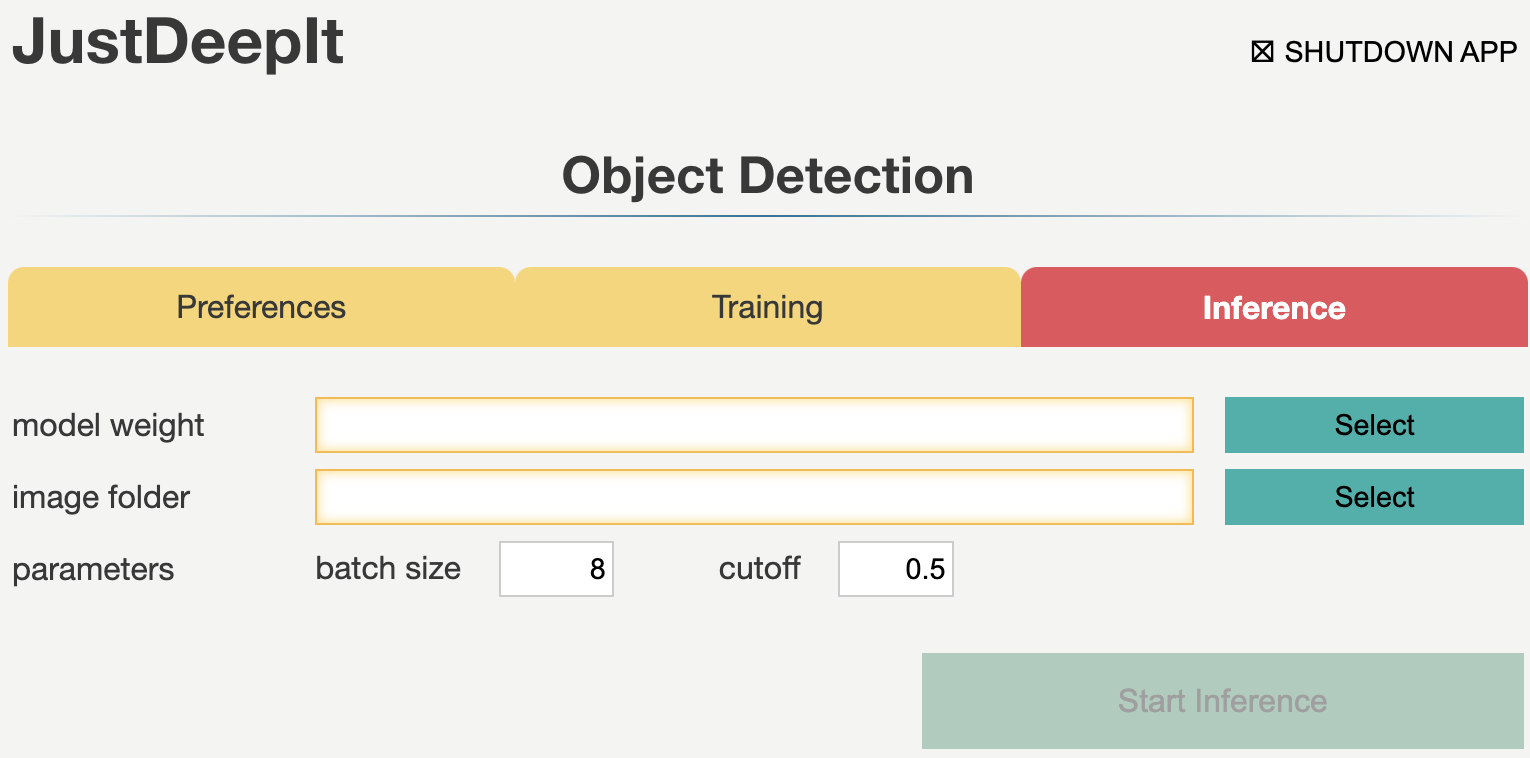
Argument |
Description |
|---|---|
model weight |
A path to a trained model weight. |
image folder |
A path to a folder contained test images. |
batch size |
Batch size. |
cutoff |
Cutoff of confidence score for inference (i.e., object detection). |
CUI
JustDeepIt implements three simple methods,
train,
save,
and inference.
train is used for training the models,
while save is used for saving the trained weight,
and inference is used for detecting objects in test images.
Detailed descriptions of these functions are provided below.
Architectures
A neural network architecture for object detection
can be initialized with class justdeepit.models.OD.
For example, Faster R-CNN can be initialized by executing the following code.
from justdeepit.models import OD
model = OD('./class_label.txt', model_arch='fasterrcnn')
To initialize Faster R-CNN with the pre-trained weight
(e.g. the weight pre-trained with COCO dataset),
the argument model_weight can be used.
Note that, the weight file (.pth) pre-trained with COCO dataset
can be downloaded from the GitHub repositories of
MMDetection
or Detectron2.
from justdeepit.models import OD
weight_fpath = '/path/to/pretrained_weight.pth'
model = OD('./class_label.txt', model_arch='fasterrcnn', model_weight=weight_fpath)
Training
Method train is used for the model training
and requires at least two arguments
to specify a folder containing the training images and annotations.
Annotations can be specified in a single file in the COCO format
or a folder containing multiple files in the Pascal VOC format.
Refer to the API documentation of train
for detailed usage.
Training a model with annotation in COCO format.
from justdeepit.models import OD
train_dataset = {
'images': '/path/to/folder/images',
'annotations': '/path/to/coco/annotation.json',
'annotation_format': 'coco'
}
model = OD('./class_label.txt', model_arch='fasterrcnn')
model.train(train_dataset)
Training a model with annotation in Pascal VOC (xml) format.
from justdeepit.models import OD
train_dataset = {
'images': '/path/to/folder/images',
'annotation' = '/path/to/folder/voc',
'annotation_format': 'voc'
}
model = OD('./class_label.txt', model_arch='fasterrcnn')
model.train(train_dataset)
The trained weight can be saved using method save,
which simultaneously stores the trained weight (.pth)
and model configuration file (.py).
Refer to the API documentation of save
for detailed usage.
model.save('trained_weight.pth')
Inference
Method inference
is used to detect objects in the test images using the trained model.
This method requires at least one argument to specify a single image,
list of images, or a folder containing multiple images.
The detection results are returned as
a class object of justdeepit.utils.ImageAnnotations.
To save the results in the COCO format,
we can use method format
implemented in class justdeepit.utils.ImageAnnotations
to generate a JSON file in the COCO format.
from justdeepit.models import OD
test_images = ['sample1.jpg', 'sample2.jpg', 'sample3.jpg']
model = OD('./class_label.txt', model_arch='fasterrcnn', model_weight='trained_weight.pth')
outputs = model.inference(test_images)
outputs.format('coco', './predicted_outputs.coco.json')
To save the detection results as images, for example,
showing the detected bounding boxes on the images, method draw
implemented in class justdeepit.utils.ImageAnnotation can be used.
for output in outputs:
output.draw('bbox', os.path.join('./predicted_outputs', os.path.basename(output.image_path)))
Refer to the corresponding API documentation of
inference,
format, and
draw,
for the detailed usage.