Salient Object Detection
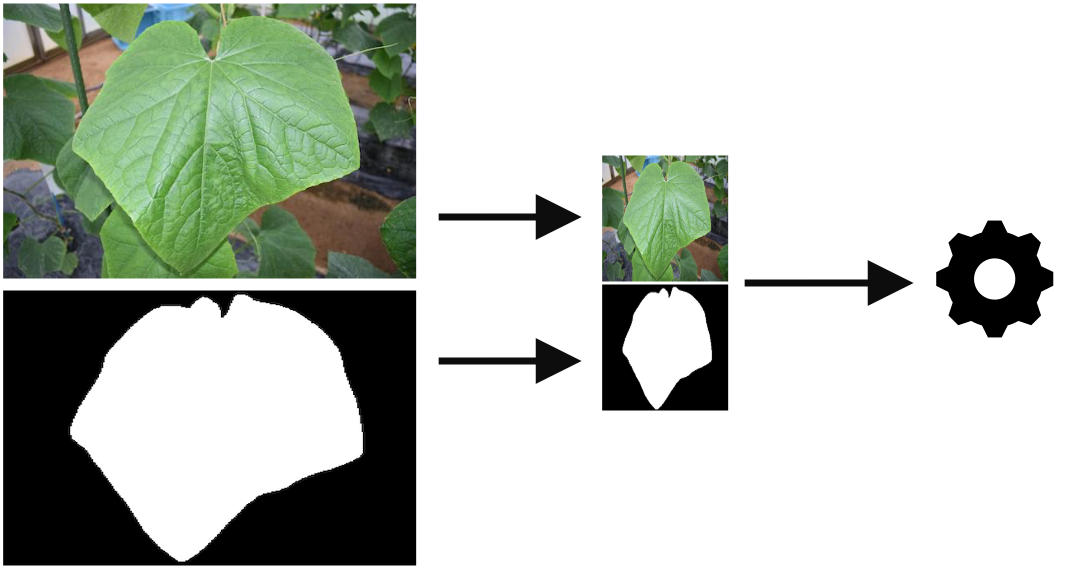
Salient object detection is typically used to identify the major object in an image. It can be applied to one-class object segmentation tasks such as background removal, plant segmentation, root segmentation, and tumor segmentation. The fowllowing image is an example of salient object detection tasks.

GUI
The GUI window for salient object detection consists of three tabs: Preferences, Training, and Inference. These tabs are used for setting common parameters, training models, and detecting objects from the test images using the trained model, respectively. Tabs Training and Inference are disabled until the settings in tab Preferences are defined.
Preferences
Tab Preferences is used for setting common parameters, such as the architecture of the detection model, number of CPUs and GPUs to be used, and the location (directory path) to the workspace. The workspace is used to save intermediate and final results. Detailed descriptions of the arguments are provided in the following table.
Argument |
Description |
|---|---|
architecture |
Architecture for salient object detection. |
CPU |
Number of CPUs. |
GPU |
Number of GPUs. |
workspace |
Workspace to store intermediate and final results. |
Training
Tab Training is used to train the model for salient object detection. It allows users to set general parameters of training, such as the optimization algorithm, optimization scheduler, batch size, and number of epochs. Detailed descriptions of the arguments are provided in the following table.
Argument |
Description |
|---|---|
model weight |
A path to store the model weight. If the file is exists, then resume training from the given weight. |
image folder |
A path to an folder which contains training images. |
annotation format |
Annotation format. |
annotation |
A path to a file (when the format is COCO) or folder (when the format is mask). |
strategy |
A training strategy. |
cropping size |
An integer of cropping size for |
optimizer |
A PyTorch optimizer. The supported optimizers can be checked from the PyTorch website. |
scheduler |
A PyTorch optimization scheduler. The supported schedulers can be checked from the PyTroch website. |
batch size |
Batch size. |
epoch |
Number of epochs. |
cutoff |
A threshold to determine the object areas. |
Inference
Tab Inference is used for segmenting objects from test images using the trained model. It allows the user to set the confidence score of salient object detection results and batch size. Detailed descriptions of the arguments are provided in the following table.
Argument |
Description |
|---|---|
model weight |
A path to model weight. |
image folder |
A path to an image or a folder contained multiple images targeted to salient object detection. |
batch size |
Batch size. |
cutoff |
Cutoff of confidence score for inference. |
strategy |
A training strategy. |
cropping size |
An integer of cropping size for |
image opening kernel size |
Kernel size for image opening process which is used for remove small white spots (e.g. noise, very small objects, etc). |
image closing kernel size |
Kernel size for image closing process which is used for remove small black spots (e.g. a small hole in the object area). |
time-series |
If the input images are taken with a fixed camera in time-series, turning on this option will give object ID by considering the time-series. |
align image |
Turning on this option, JustDeepIt will align all images by position before any post-processings. |
CUI
JustDeepIt implements three simple methods,
train,
save,
and inference.
train is used for training the models,
while save is used for saving the training weights,
and inference is used for salient objects detection against test images.
Detailed descriptions of these functions are provided below.
Training
Method train is used for the model training.
It requires user to specify training images, annotation, and annotation format.
The annotations can be specified in a single file in the COCO format
or a folder containing multiple mask images.
Refer to the API documentation of train for the detailed usage.
Training a model using images with masks.
from justdeepit.models import SOD
model = SOD()
model.train('./train_images', './mask_images', 'mask')
Training a model using images with the annotations in COCO format.
from justdeepit.models import SOD
model = SOD()
model.train('./train_images', './annotation.coco.json', 'COCO')
The training weights can be saved using method save,
which stores the trained weights.
model.save('final_weight.pth')
Inference
Method inference
is used to perform salient object detect from the test images using the trained model.
This method requires at least one argument to specify a single image,
list of images, or a folder containing multiple images.
import skimage.io
from justdeepit.models import SOD
test_images = ['sample1.jpg', 'sample2.jpg', 'sample3.jpg']
model = justdeepit.models.SOD('final_weight.pth')
outputs = model.inference(test_images)
To show the detection results as images, for example,
showing the detected contours on the images,
method draw
implemented in class justdeepit.utils.ImageAnnotation can be used.
Here is an example to show the detection result of the first image.
im0 = outputs[0].draw('contour')
skimage.io.imshow(im0)
To save the detection results as images,
specify the path to the method draw.
Here is an example to save the detection results of all test images.
for test_image, output in zip(test_images, outputs):
mask_fpath = os.path.splitext(test_image) + '_mask.png'
output.draw('mask', mask_fpath)
Refer to the corresponding API documentation of
inference
and draw
for the detailed usage.
Training Strategy
As the U2-Net implementation in JustDeepIt requires images of 288 x 288 pixels, JustDeepIt uses resizing or random cropping to handle training images of various sizes. resizing scales the training images and annotations (i.e., masks) to 288 x 288 pixels for U2-Net training. This approach is used to process images containing one or few large objects.
random cropping randomly extracts small areas of p x p pixels from the original images and annotations with a random angle. The areas of p x p pixels are then resized to 288 x 288 pixels for U2-Net training. p can be specified by the user based on the complexity of the target images and tasks. This approach is used to treat images containing several or many small objects.

Detection Strategy
Similar to training, two approaches can be adopted for salient object detection: resizing and sliding. resizing is similar to the corresponding training approach. Hence, the input image is resized to 288 x 288 pixels to perform detection, and the original size is restored after detection. If the model is trained using resizing, resizing approach should be set for detection.

sliding crops square areas of p x p pixels from the input image from the top left to the bottom right of the image and resizes the areas to 288 x 288 pixels. Next, salient object detection is performed on the resized square areas. After all the areas are processed, their results are combined (restored) into a single image. This approach corresponds to random cropping during training. Thus, if the model is trained using random cropping, sliding should be used for detection.
